1.宏观架构图
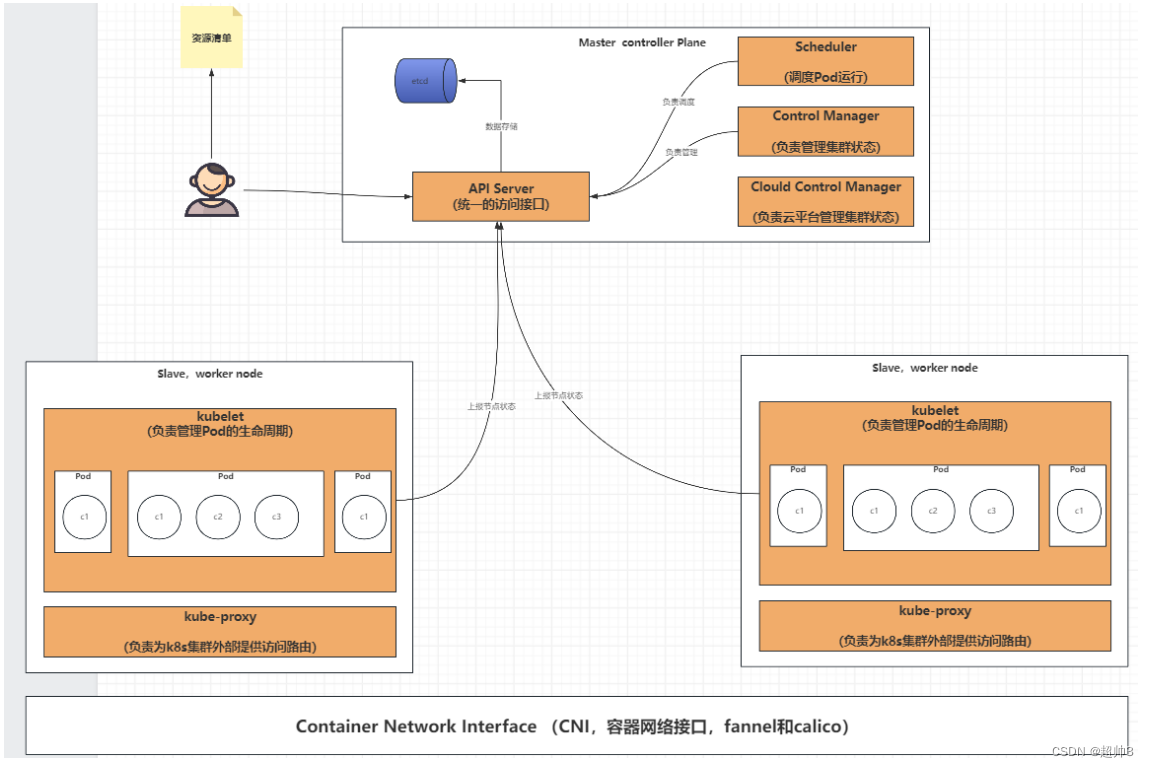
2.角色详情
2.1 Master(Controller Plane)
早期是叫 Master 节点,后期改名为 Controller Plane,负责整个集群的控制和管理
Master 不会干活的(当然你让它干也是会干的,涉及到污点容忍),而是起到访问入口(API Server)、调度协调(Scheduler)、管理作用(Control Manager)。
-
API Server
kube-apiserver,集群的统一入口,各组件协调者,以RESTFUL API提供接口服务,所有对象资源的增删改查和监听操作都交给APIServer处理后再提交给etcd存储。
-
Scheduler
kube-scheduler 根据调度算法为新创建的Pod选择一个Node节点,可以任意部署,可以部署在同一个节点上,也可以部署在不同的节点上。调度决策考虑的因素包括单个 Pod 及 Pods 集合的资源需求、软硬件及策略约束、 亲和性及反亲和性规范、数据位置、工作负载间的干扰及最后时限。
-
Control Manager
Kube-controller-manager,处理集群中常规后台任务,一个资源对应一个控制器,而ControllerManager就是负责管理这些控制器的。
- 节点控制器(Node Controller):负责在节点出现故障时进行通知和响应
- 任务控制器(Job Controller):监测代表一次性任务的 Job 对象,然后创建 Pod 来运行这些任务直至完成
- 还有其他,rs,rc,sts, CronJob等
-
Cloud Controller Manager
用在云平台上的Kube-controller-manager组件。如果我们直接在物理机上部署的话,可以不使用该组件。
-
Etcd
分布式键值存储系统,用于保存集群状态元数据信息,比如Pod,Service等对象信息。这个数据库是可以单独拿出来部署,只需要API server可以连接到该分布式数据库集群即可
2.2 Slave(worker node)
早期叫 slave 节点,后期改名为 Worker node,负责执行和运行工作负载的节点
slave(worker node) 节点默认不得超过 5000个,也就是集群中不能超过5000台机器,如果超过则多集群管理
容器不得超过 30W个
单个节点的Pod数量默认不能超过 110 个,服务器规格高的话,可以调大,默认是不需要修改的
-
kubelet
可以理解为Master在工作节点上的Agent,管理本机运行容器的生命周期,比如创建容器,Pod挂载数据卷,下载secret,获取容器的节点状态等工作。kubelet 将每一个Pod转换成一组容器。会定期收集这些信息上报给API Server,APIserver收到后会存储到etcd存储中。
-
kube-proxy
在工作节点上实现Pod网络代理,维护网络规则和四层负载均衡工作。换句话说,就是用于负责Pod网络路由,用于对外提供访问的实现。可以找到你关心的项目所在的pod节点。
-
POD
用户划分容器的最小单位,一个POD可以存在多个容器
3. kubernets 部署方式
3.1 目前生产环境部署kubernetes集群主要由两种方式
3.1.1 kubeadm 方式部署
kubeadm是一个K8S部署工具,提供kubeadm init和kubeadm join,用于快速部署kubernetes集群。
kubeadm init 初始化一套集群
kubeadm join 加入已存在集群
3.1.2 二进制方式部署
从GitHub下载发行版的二进制包,手动部署每个组件,组成kubernetes集群。
集群规模较多的话,推荐使用二进制部署。
3.2 其他部署方式的途径
-
yum:
已废弃,目前支持的最新版本为2017年发行的1.5.2版本。
-
minikube:
适合开发环境,能够快速在Windows或者Linux构建K8S集群,单点部署。
-
rancher:
基于K8S改进发行了轻量级K8S,让K3S孕育而生。阉割版
-
KubeSphere:
青云科技基于开源KubeSphere快速部署K8S集群。可在现有的K8S集群上面安装部署,提供图形化管理界面以及可视化监控。
-
kuboard:
也是对k8s进行二次开发的产品,新增了很多独有的功能。
-
kubeasz:
使用ansible部署,扩容,缩容kubernetes集群。
-
第三方云厂商:
比如aws,阿里云,腾讯云,京东云等云厂商均有K8S的相关SAAS产品。
以上基本都是基于K8S二次开发的产品,有兴趣的可以自行了解一下